Fixing serverless with a $5 VPS
How we are supporting our serverless API with servers to scale beyond the limits of serverless.
Written by
Andreas Thomas
Published on
Serverless solved many issues and created many more. It's a great way to build applications that scale, but it can only scale as far as your other services can. For example, if you're using a serverless function to process data, and that data is coming from a database that can only handle 100 requests per second, then your serverless function is effectively capped at 100 requests per second as well.
So why do we use serverless if it's limited by servers? Well in our case, we use Cloudflare workers for our API for their global low latency. That's it, everything else we build around it, is just to make it work.
The problem
Our API emits multiple different events, such as the outcome of a verification, or a rate-limit being hit. We use Tinybird for all of our analytics, and we were sending each event individually to Tinybird. This is easy on the worker's side because you just fire and forget.
1executionContext.waitUntil(tinybird.ingestKeyVerification({ ... }))The problem is that Tinybird has a 1k requests per second ingest limit, and we were hitting that limit regularly. The obvious solution is to batch the events and send them in a single request
That's where the rabbit hole started...
Batching in Cloudflare workers
Cloudflare workers are great, but they are not designed for batching. You can't just wait for a few seconds and then send a batch of events to Tinybird. You have to send the events as they come in, or you risk losing the event as the underlying worker can be recycled at any time after the execution ended.
Let's look at the options I explored:
- Cloudflare Queues, D1 or Durable Objects
- Cloudflare Logpush
- Cloudflare Analytics Engine
- Clickhouse Cloud
- Kafka
- Tinybird Enterprise
- VPS
Cloudflare Queues, D1 or Durable Objects
I group these 3, cause they all solve the problem pretty well, but are just too expensive for our use case. Here's some napkin math to illustrate my point:
Worker invocations are charged at $0,30 per million, there's also a charge for CPU time, so let's just say we're paying around 40 cents per million requests. Cloudflare queues are $1.20 per million messages (assuming you don't need to retry), D1 and Durable Objects are similarly priced.
Each worker invocation produces on average 2 events, but inside the worker, we can batch them and send a single message through the queue. So for 1 million API requests, we'd be paying $0.40 for the worker invocations, and $1.20 for the queue, for a total of $1.60. Queues are just too expensive relative to the cost of the worker invocations.
Now $1.60 per million requests doesn't sound like a lot, but we need to have good margins and then our customers would have to add more margin on top of that. We want to make building APIs more accessible to everyone, so we need to keep our costs low.
Cloudflare Logpush
Cloudflare Logpush is pretty nice for sending logs to your sink. The problem is that it's pretty slow, we're seeing around 2-3 min of delay between logging something and it appearing in our sink. This is not acceptable for our real-time analytics.
There are also some other limitations that make it hard to use:
- Message size: Maximum of 2056 characters per log line (That's not really that much data if you encode it in JSON)
- Array limit: 20 elements (I still don't know what this refers to)
- Log message array: A nested array with a limit of three elements
We do use Logpush for other internal metrics to aggregate and send them to Axiom.co, where the latency doesn't matter as much and we'd be fine to drop some events if we exceed some limits. Let us know if you'd like to see a blog post about that implementation.
Clickhouse Cloud
I was surprised how good clickhouse cloud was, I expected an AWS-like experience but they made it pretty nice and easy to use. The problem for us is that it didn't work so well with thousands of small requests per second. Clickhouse really likes receiving large batches of 10k-100k rows in a single request, so it can optimize the writes to disk, and we need to do the opposite. Source
Cloudflare Analytics Engine
When I first heard about the Analytics Engine, I thought it was the solution to all of our problems. Clickhouse natively on Cloudflare sounds like a dream come true. The reality is far from that though. At Cloudflare's scale both in terms of usage but also in terms of the number of different customer needs, it's hard to build a product that fits everyone. They made some harsh tradeoffs to make it work for everyone, and in doing that made it only work for a few. At least in its current state. I'm happy to look past the API design and just write a wrapper around it, but I was just bouncing from one undocumented problem to the next.
Anyways, Analytics Engine would have been a pretty nice solution due to its pricing. It's $0.25 per million rows ingested and $1 per million queries (regardless of the number of rows returned). This is a pretty good deal, and my idea was to use it as a buffer. I'd ingest the events into the Analytics Engine and then run a SELECT * query every few seconds to get the events and send them to Tinybird. The problem with that is: how do I know which events I've already processed without having to keep track of every single row?
I tried a few different approaches, but they all came down to the fact that there is no guarantee of how quickly Cloudflare commits rows to the Analytics Engine. It could take a few seconds, or even a minute, making it hard to build a reliable system to get the events out of it.
Kafka
Kafka would be pretty good for this use case, but sending many small messages to Kafka over HTTP is not really what it's designed for. We're back to the same problem of not being able to batch the events in the worker. I've heard from teams who run Cloudflare workers + Kafka in production right now, and they're not happy with the solution as they scale up. I have not done my own research on this but instead trusted their judgment.
Tinybird Enterprise
Perhaps the most obvious solution would be to just ask Tinybird to raise the limit for us. So we did. They were very helpful and offered a custom solution, albeit at a price point that is not commercially viable for us yet. We don't need the full Tinybird enterprise experience, we just need a higher request limit. All other metrics are well within the current limits.
The solution
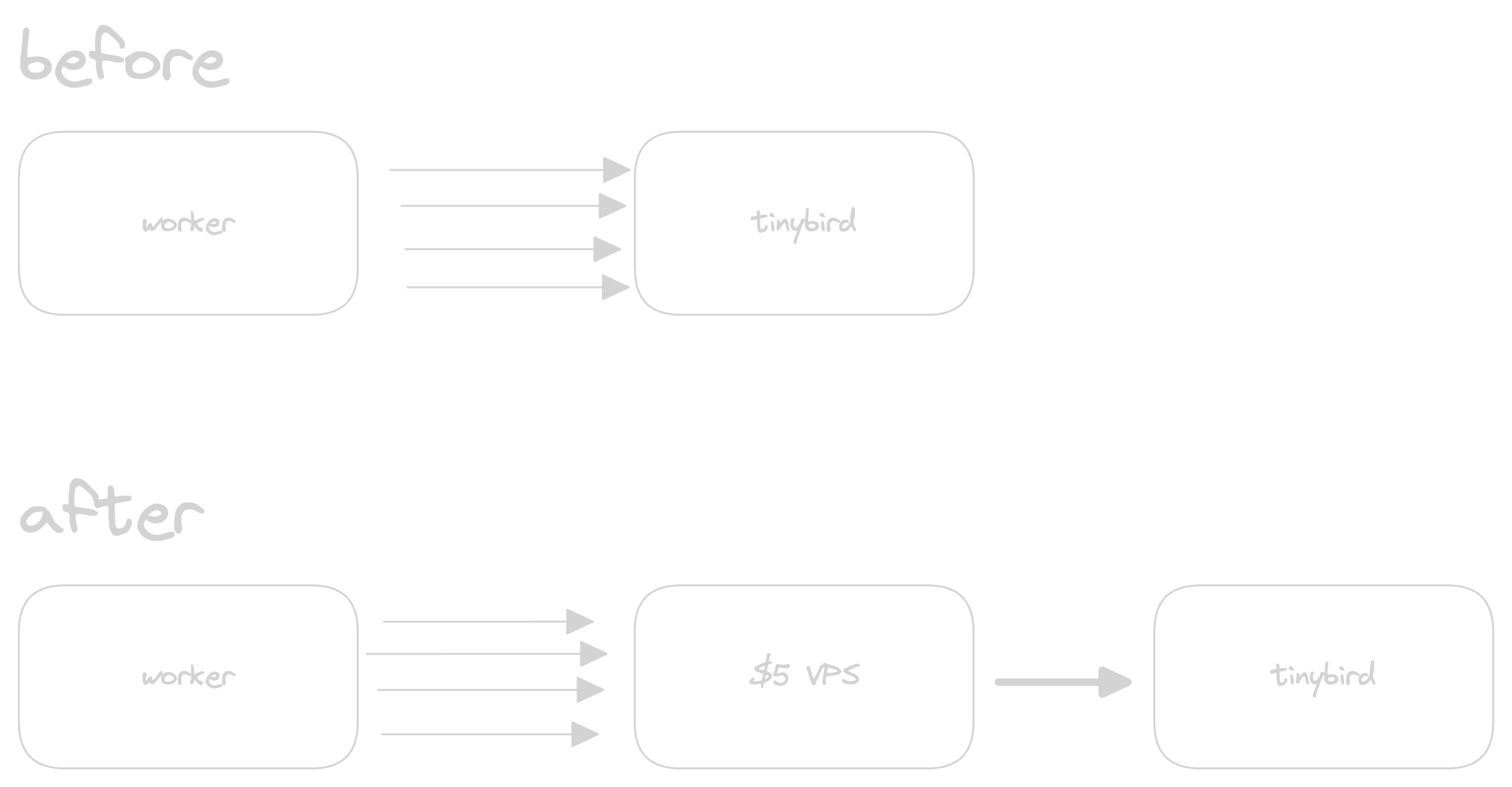
If we can't batch the events in a serverless function, then let's do it on a server instead. We've created a simple Go application that is api-compatible with Tinybird's /v0/events API. It accepts NDJSON events, buffers them, and then sends a batch to Tinybird in a single request.
Because it's compatible, we don't need to change anything in our worker code, we just use a different TINYBIRD_URL and TINYBIRD_TOKEN and we're good to go.
Deployment
We chose to deploy this proxy on Koyeb because it's super easy and they have autoscaling. I know others do too, but we were already familiar with Koyeb. We just push our code to GitHub, and Koyeb takes care of the rest.
If you want to run this yourself, just choose a VPS provider you're comfortable with, and run the docker container.
Quickstart
All you need is docker and your Tinybird token. You can run it like this:
1docker run -p 8000:8000 -e TINYBIRD_TOKEN="abc" ghcr.io/unkeyed/tinybird-proxy:latestConfig
See the readme for all available options.
By default, the proxy will try to send batches of max 100k rows or every second, whichever happens first. The buffer size is 1 million events, to minimize data loss in case of a machine failure. If the buffer is full, the proxy will not accept more data until it's flushed.
Performance
We've tested this with over 8k RPS and it barely broke a sweat. We're currently running this on 1-4 autoscaling instances with 2 vCPUs and 2GB of RAM.
Conclusion
Using a proxy solved all of our problems:
- Supports our current and expected load for the foreseeable future
- Low latency for our real-time analytics
- Cheap (less than $50 per month)
- Easy to scale
We're still using serverless where it makes sense and Cloudflare workers play a critical role in ensuring our API is fast and reliable, but some of the supporting infrastructure can be run on servers for a fraction of the cost.



Protect your API.
Start today.
2500 verifications and 100K successful rate‑limited requests per month. No CC required.